
これに従っておけば、動くはず。古めのドライバが必要。
Three Ways to Generate AI Art Using Intel® Arc™ GPUs
nvidiaでは起きなかったエラーなどいろいろあったので挙げていく。
使用可能なモデルは.safetensors限定?
.ckpt読み込んだけど生成できず。チュートリアル動画ではモデルが全て.safetensorsだったからそういうことだろうと思う。
Euler a には触れるな⁉
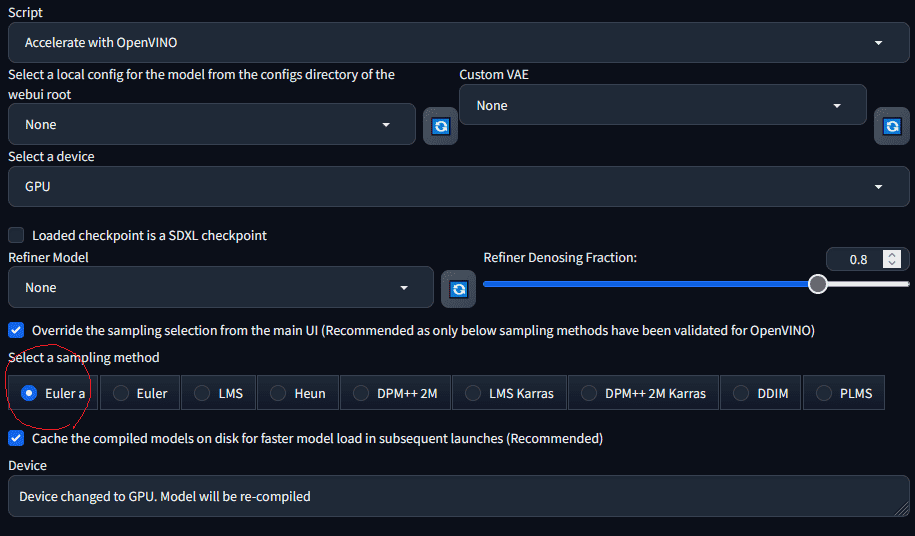
*** Error completing request
*** Arguments: ('task(qjmlwism8qzwkof)', 'masterpiece,best quality,masterpiece,asuka langley sitting cross legged on a chair,anime', 'lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name', [], 28, 'DPM++ 2M SDE', 10, 1, 7, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, 'Use same checkpoint', 'Use same sampler', '', '', [], <gradio.routes.Request object at 0x0000013DA3B3B6A0>, 1, False, '', 0.8, 2573754500, False, -1, 0, 0, 0, 'None', 'None', 'GPU', True, 'Euler a', True, False, 'None', 0.8, False, False, 'positive', 'comma', 0, False, False, '', 1, '', [], 0, '', [], 0, '', [], True, False, False, False, 0, False) {}
---
---いろいろ書いてあるけど意味不明---
---いろいろ書いてあるけど意味不明---
---いろいろ書いてあるけど意味不明---
---
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
import torch._dynamo
torch._dynamo.config.suppress_errors = True
こんなエラーを吐いてしまう。俺だけだといいけど。
Euler a 以外では大丈夫みたい。
最初の生成のみ時間がかかる
最初の推論では、最適なパフォーマンスを得るためにモデルをコンパイルする。
Accelerate with OpenVINO の Note より
コンパイルは最初の実行でのみ行われるため、最初の推論(またはウォームアップ推論)は、それ以降の推論よりも遅くなります。
正確な性能測定のためには、この遅い最初の推論は通常の実行時間を反映しないため、除外することを推奨します。
分解能、バッチサイズ、デバイス、またはDPM++やKarrasなどのサンプラーが変更された場合、モデルは再コンパイルされます。
再コンパイル後、後の推論は新しくコンパイルされたモデルを再利用し、より高速な実行時間を実現します。
そのため、設定変更後の最初の推論は遅くなり、それ以降の推論は最適化されたコンパイル済みモデルを使用して高速に実行されるのが普通です。
1分くらい待つ。チュートリアル動画では数秒で終わってたな…。
それ以降はモデルを変えない限り普通に生成できる。
初回は+1分。
ノートパソコンだと4枚で20分くらいだったから、凄まじい速さで感動するわ。
モデルを頻繁に変える人はその度待たされるから嫌かもしれない。
終わり
loraとかcontrol netは試そうと思う。その前にSD.NEXTを使ってみたくなった。gimpでも使えるらしい。初回の待ち時間が気になるような…こうして人は短気になっていくのか。気長に読書して待ってた頃が懐かしい。


コメント